PointPillars 论文笔记
PointPillars
PointPillar的网络结构
(D, P, N)–> (C, P, N) –> (C, P) –> (C, H, W) –> (6C, H/2, W/2) –> bbox
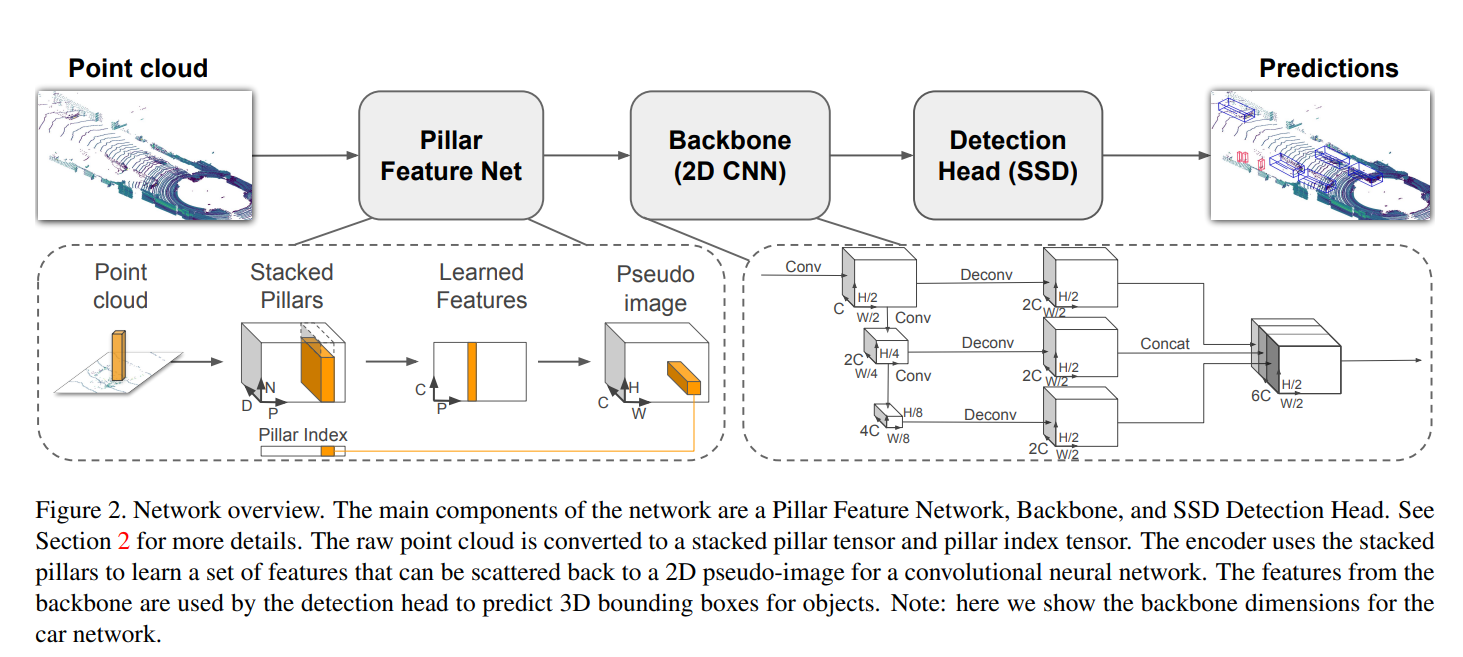
- 提出一种新的encoding points的方式: Pillar
- fast version– 平均62Hz , faster version– 105 Hz, 超过SECOND三倍。(激光雷达工作频率通常是5HZ/10HZ/20Hz,105HZ的LIDAR现实中比较少)
- 对于模型能达到的速度和真实自动驾驶场景能达到的速度做了一些讨论
PointPillars-car:
PointPillars-car是专门用于检测汽车的模型,它只需要检测汽车这一种目标类别,因此输出结果只包含汽车的检测框和相关的属性信息
PointPillars-3class:
PointPillars-3class则可以检测三种目标类别,包括汽车、行人和自行车,因此输出结果会同时包含这三种目标的检测框和相关属性信息。
Pillar 方式编码
(D, P, N)–> (C, P, N) –> (C, P) –> (C, H, W) –> (6C, H/2, W/2) –> bbox
– 张量化
point clouds –> (D, P, N)
p : max number of pillars (P),最大pillars (P) 具体使用 12000
N : max number of points per pillar (N),每个pillars的最大点数 (N), 具体使用100
D : 是 dimension点云的表示(D=9 dimension):
$$
(x,y,z,r,x_c,y_c,z_c,x_p,y_p)
$$
$$ x,y,z$$为点云的真实坐标信息和反射强度,$$x_c,y_c,z_c$$为该点云所处Pillar中的所有点的几何中心;$$x_p,y_p$$为$$x-x_c,y-y_c$$,反应了点与几何中心的相对位置。
- 特征提取网络:应用线性层(linear layer),然后应用 BatchNorm 和 ReLU 以生成 (C, P, N) 大小的
张量。
原来的维度是D=9,经过Pillar Feature Net(特征提取网络)后,得到新的维度C,(D, P, N) –> (C, P, N)
按照Pillar所在维度进行Max Pooling操作,即获得了(C, P)维度的特征图。
特征被编码后,特征会被分散到原来的pillar的位置,创建一个尺寸为(C, H, W),其中H和W表示画布的长度和高度。
– Backbone (2D CNN)
- 指在输入图像上进行特征提取的网络核心结构。
- Backbone 通常由一系列卷积层组成,通常以分层结构组织,学习检测输入图像中越来越复杂和抽象的特征。然后,这些特征被传递给一个或多个执行分类任务的全连接层。
- Backbone 结构的选择对网络的性能有很大的影响,包括准确性和计算效率方面。流行的二维CNN的骨干架构包括VGG、ResNet、Inception和MobileNet等。
- 在许多情况下,骨干结构可以在一个大的数据集上进行预训练,如ImageNet,以学习一套通用的特征,这些特征可以为特定的任务进行微调。这种方法被称为迁移学习,在为特定的应用开发和训练一个新的CNN时可以节省大量的时间和计算资源。
- mmdetection3D中针对KITTi数据集使用的Backbone是SECFN,下面只放KITTI的结果,其他结果(nuScenes/Lyft/Waymo)详见https://github.com/open-mmlab/mmdetection3d/blob/main/configs/pointpillars/README.md
Results and models
KITTI
Backbone Class Lr schd Mem (GB) Inf time (fps) AP Download SECFPN Car cyclic 160e 5.4 77.6 model | log SECFPN 3 Class cyclic 160e 5.5 64.07 model | log
(C, H, W) –> (6C, H/2, W/2)
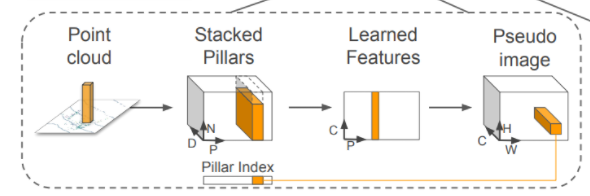
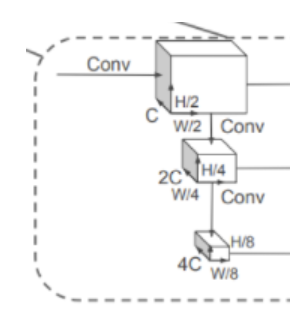
第一个网络:自上而下的网络以越来越小的空间分辨率产生特征,同时提升特征图的维度
第二个网络:对自上而下的特征进行上采样和串联。
之所以选择这样架构,是因为不同分辨率的特征图负责不同大小物体的检测。比如分辨率大的特征图往往感受野较小,适合捕捉小物体(在KITTI中就是行人)。
– Detection Head
文章中使用后Single Shot Detector(SSD)进行三维物体的检测设置,类似于SSD
- 使用二维联合交集(IoU)将先验框和ground truth相匹配
- boundingbox的高度H不用于匹配,相反给定一个二维的匹配,使高度和仰角成为额外的回归目标
1 | |
Network
$S$:相对于原始输入伪图像的测量值
The encoder network jas C = 64 output features,
First block (S = 2 for car, S = 1 for pedestrian/cyclist).
Both network consists of three blocks, Block1(S, 4, C), Block2(2S, 6, 2C), and Block3(4S, 6, 4C).
three blocks,每个区块采用上采样步骤进行升采样,Up1(S, S, 2C), Up2(2S, S, 2C), and Up3(4S, S, 2C),然后,三个区块被串联起来,形成Detection Head的6C特征
Loss funtion
PointPillar use the same loss function introduced in SECOND.
PointPillar的loss function和SECOND相似,每个3D的Boundingbox用一个7维的向量表示,分别为($x,y,z,w,h,l,\theta $),其中($x,y,z$)为中心,($w,h,l$)为尺寸数据,$\theta$为方向角。
检测框回归任务中要学习的参数维这7个变量的偏移量:
$\Delta x=\frac{x^{gt}-x^{a}}{d^{a}}$;$\Delta y=\frac{y^{gt}-y^{a}}{d^{a}}$;$\Delta z=\frac{z^{gt}-z^{a}}{h^{a}}$;
$\Delta w=log\frac{w^{gt}}{w^{a}}$$;\Delta l=log\frac{l^{gt}}{l^{a}}$;$\Delta \theta=sin(\theta^{gt}-\theta^{a})$
$x^{gt}$:ground truth
$x^{a}$:anchor boxes(锚定框)
$d^{a}=\sqrt{(w^{a})^{2}+(l^{a})^{2}} $
$$
L_loc=\sum_{b\in (x,y,z,w,l,h,\theta)}SmoothL1(\Delta b)
$$
由于角度定位损失不能区分翻转的boxes,所以文章使用了一个关于离散化方向的softmax分类损失,$L_dir$(离散方向),使得网络能够学习到heading的方向。
对于object classification loss,使用focal loss:
$$
L_cls=-\alpha_a(1-\beta^{a})^{\gamma}logp^{a}
$$$p^{\alpha}$为锚点为某个类的可能性(置信度),其中$\alpha=0.25$$\gamma=2$,最终损失函数为:
$$
L=\frac{1}{N_pos}(\beta_locL_loc+\beta_clsL_cls+\beta_dirL_dir)
$$其中$N_pos$是positive anchors的数量,$\beta_los=2$,$\beta_cls=1$,$、beta_dir=0.2$
Dataset
- PointPillar only train on lidar point clouds in KITTI dataset, but compare with fusion methods that use both lidar